Whether you automatically access the data conversion function upon uploading data or choose it from the Data menu, there are two possible RDS data formats:
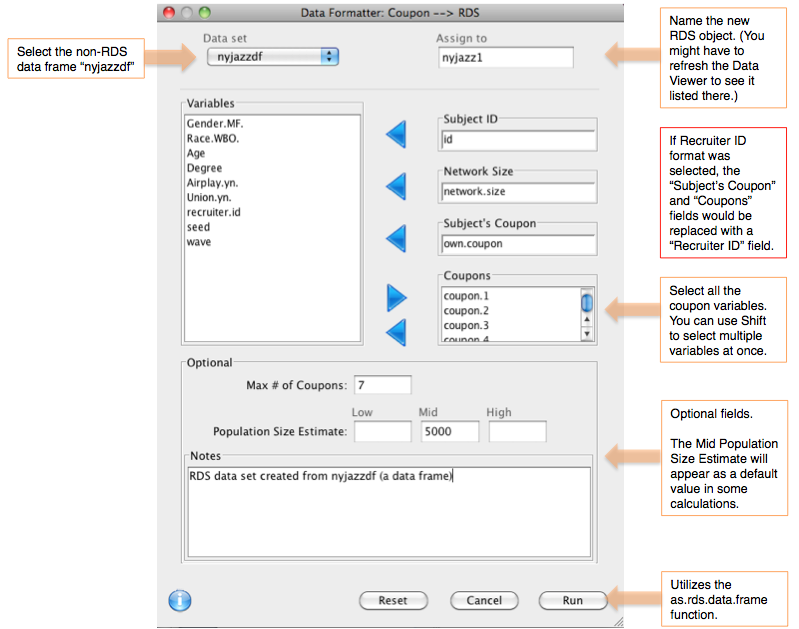
In this format there are several columns in the data containing coupon numbers. One column is for each respondent's own coupon, and the others (e.g. coupon.1, coupon.2, etc.) list the coupons they may have distributed. Thus, the recruitment path is stored through the coupon numbers. The seeds generally have own coupon numbers of 0, NA or something similar. Upon conversion, columns identifying each respondent's recruiter ID, wave and seed are created if not already present.

Rather than tracking recruitment paths through coupons, in this format a Recruiter ID column records the subject ID of the recruiter for each respondent. Seeds are identified by a shared recruiter ID such as 0. Upon conversion, columns identifying each respondent's wave and seed are created if not already present.

Suppose you have imported the data frame nyjazzdf from a non-RDS file format (see RDSAnalystImportRDSData). You could convert it to the RDS data object "nyjazz1" as follows:
 Deducer: A GUI for R
Deducer: A GUI for R